
Recently Uncle Bob mentioned that there is so much
time wasted by developers on "fiddling around with time accounting tools". That's so true. During my 11 years of professional software development I had the opportunity to witness different approaches used by companies. I understand the need to monitor and control spent times but I hate wasting my own time on time accounting stuff. So I always try to minimise the time needed by automating the process of filling in the forms (if possible). Remember
Terence John Parr's quote: "Why program by hand in five days what you can spend five years of your life automating?" :-)
Spread YourselfOf course, if you have to track times of your tasks, you have to write them down. If you work on different tasks during the day then spreadsheets work best for that, especially if you spend some time automating them further. For example you may use VBA to write some Excel Macros. (Or even use some
Ruby OLE magic.) Early in my career I was lucky to meet
Andreas, who provided me with his detailed Excel sheet.
Since then I have been using it. It's just great. The most useful feature is adding a new line with one key shortcut (
CTRL-T). The new line is filled with the current date and the current (rounded) time or the ending time of the last task. This makes entering new lines extremely fast:
CTRL-T, fill project and subproject number, add description. Andreas' sheet worked so well for everybody that it became the official time accounting tool for all employees later. (Thank you Andreas for your great spreadsheet!)
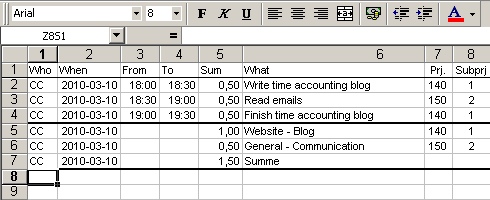
Another company I worked with did not have any kind of time accounting. That was nice for a change, but I did not believe in it and kept using my macro infested Excel sheet. Later, when they started using their own tool based on Oracle Forms, I wrote a little application that imported the lines from my sheet into the database. It was quite simple (less than 100 lines) to read a CSV, do some translations and insert the data into a database. Unfortunately companies usually do not allow employees to write directly into their time accounting database (for obvious reasons).
Timed OverkillLast year, while working for a big bank, I experienced the overkill of time accounting. There were
three different systems. Project management used
XPlanner to track task progress. XPlanner is a web application. I could have "remote controlled" it using plain HTTP
GETs and
POSTs, but that would have been cumbersome. So I used
Mechanize to create a small API to access XPlanner. The API is outlined by the following code, which was written for XPlanner version 0.6.2. To save space I removed all error handling. (The current XPlanner version features a SOAP interface, so remote controlling it gets even simpler.)
class XplannerHttp
PLANNER = "#{HOST}/xplanner/do"
def initialize
@agent = WWW::Mechanize.new
@agent.redirect_ok = true
@agent.follow_meta_refresh = true
end
# Login to XPlanner web application.
def login(user, pass)
login_page = @agent.get("#{PLANNER}/login")
authenticate = login_page.form_with(:name => 'login/authenticate')
authenticate['userId'] = user
authenticate['password'] = pass
authenticate['remember'] = 'Y' # set cookie to remain logged in.
authenticate.click_button
end
# Book for a task with _taskid_ (5 digits).
# _date_ is the date in "YYYY-MM-DD" format.
# _hours_ is the time in decimal hours in format "0,0".
def book_time(taskid, date, hours)
task_page = @agent.get("#{PLANNER}/view/task?oid=#{taskid}")
# open edit time
add_link = task_page.links.find do |l|
l.href =~ /\/xplanner\/do\/edit\/time\?/
end
edit_page = add_link.click
# add new times and submit
timelog = edit_page.form_with(:name => 'timelog')
c = timelog['rowcount'].to_i-1
timelog["reportDate[#{c}]"] = date
timelog["duration[#{c}]"] = hours.to_s
timelog["person1Id[#{c}]"] = '65071' # id of my XPlanner user
timelog.click_button
end
end
Once the API was in place, a simple script extracted the values from the spreadsheet (in fact from an FX input field) and booked it. I just used XPlanner ids as subprojects and copied the cumulated sums of my Excel into the input field.
bot = XplannerHttp.new
bot.login(USER, PASS)
text.split(/\n/).each do |line|
parts = line.scan(SUM_LINE).flatten
parts[1] = parts[1].sub(/,/, '.').to_f
bot.book_time(parts[2], parts[0], parts[1])
# => bot.book_time(65142, '2009-01-22', '1,5')
end
The second application was used by the HR department to monitor working and extra hours. This was a web application using frame sets and Java Script. Mechanize does not (yet?) support Java Script, so I had to look somewhere else. I started remote controlling my browser by OLE automation, which turned out to be too difficult (for me). Fortunately
other people have done a great job creating
Watir, which does exactly that. So here we go (again without any error handling):
class StimeIe
def initialize
@browser = Watir::Browser.new
end
def login(user, pass)
@browser.goto("#{STIME}")
@browser.wait
login_frame = @browser.frame(:index, 4)
login_frame.text_field(:name, 'Num').set(user)
login_frame.text_field(:name, 'Password').set(pass)
login_frame.button(:name, 'Done').click
@browser.wait
end
# Book for a day with _date_ in format "DD.MM.YYYY".
# _from_ is the time of coming in "HH:MM" format.
# _to_ is the time of leaving in "HH:MM" format.
def book_time(date, from, to)
navigate_to 'Erfassung/Korrektur'
input_frame = @browser.frame(:index, 4)
if input_frame.text_field(:name, 'VonDatum').text != date
input_frame.text_field(:name, 'VonDatum').set(date)
@browser.wait
end
# add new times and submit
input_frame.text_field(:name, 'VonZeit').set(from)
input_frame.text_field(:name, 'BisZeit').set(to)
input_frame.button(:id, 'Change').click
input_frame.button(:id, 'Done').click
@browser.wait
end
# Logout and close the browser.
def close
navigate_to 'Abmelden'
@browser.close
end
def navigate_to(link_name)
nav_frame = @browser.frame(:index, 3)
nav_frame.link(:text, link_name).click
@browser.wait
end
end
A little script would extract the first and last time of a day from the spreadsheet and call the bot:
bot = StimeIe.new
bot.login
times = ...
times.keys.sort.each do |date|
from_until = times[date]
bot.book_time(date, from_until.from, from_until.until)
# => bot.book_time('09.03.2009', '09:00', '18:00')
end
bot.close
A Nut to CrackThe third application was the hardest to "crack": A proprietary .NET application used by controlling. I spent (read wasted) some time reverse engineering server and database access. (
.NET Reflector is a tool worth knowing. It is able to decompile .NET DLLs.) Then I started scripting the application with
AutoIt. AutoIt is a freeware scripting language designed for automating Windows GUIs. Using
win32ole AutoIt can be scripted with Ruby:
class Apollo
APOLLO_EXE = 'Some.exe'
APOLLO_WIN_NAME = 'APOLLO'
CTID = '[CLASS:WindowsForms10.SysTreeView32.app.0.19c1610; INSTANCE:1]'
def initialize
@autoit = WIN32OLE.new('AutoItX3.Control')
end
# Open with local Windows credentials.
def login
@autoit.Run(APOLLO_EXE)
# Wait for the exe to become active.
@autoit.WinWaitActive(APOLLO_WIN_NAME)
end
# Book for an _apo_ (5 digits and decimals).
# _text_ is the name of the sub-item.
# _date_ is the date in "DD.MM.YYYY" format.
# _hours_ is the time in full hours.
# _mins_ is the time in remaining minutes.
def book_time(apo, text, date, hours, mins)
# select the tree control
@autoit.ControlFocus(APOLLO_WIN_NAME, '', CTID)
# select the APO number
@autoit.Send(apo)
@autoit.Send('{RIGHT 5}')
...
# continue with a lot of boring code
# selecting controls and sending keystrokes.
end
def close
@autoit.WinClose(APOLLO_WIN_NAME)
@autoit.WinWaitClose(APOLLO_WIN_NAME)
end
end
 Mite
MiteRecently I happened to use
mite. It claims to be an "advanced, yet simple tool to help you get things done". Well that's true. It's easy to use and has only the most basic features needed for time accounting. More important there is an
API for developers. Good. Even better there is an official
Ruby library for interacting with the RESTful mite.api:
mite-rb. Excellent.
No need to change my good old spreadsheet. Using a new class
MiteBot instead of
XplannerHttp and friends the driver script looked quite similar.
class MiteBot
# Mapping spreadsheet activities to mite project names.
CATEGORIES = {
:default => 'Main Product',
'Meeting' => 'Meeting',
...
}
def initialize
Mite.account = ACCOUNT # your mite. account
end
# Login to the mite web application with _key_
def login(key)
Mite.key = key
end
# Book a task in _category_ with detailed _comment_
# _date_ is the date in "DD.MM" format.
# _hours_ is the time in decimal hours in format "0,0".
def book_time(date, hours, comment, category='')
key = if category =~ /^.+$/ then category else :default end
proj_name = CATEGORIES[key]
# parse date
day, month = date.split(/\./).collect{ |i| i.to_i }.to_a
timestamp = Date.new(YEAR,month,day)
# parse hours
minutes = (hours.to_s.sub(',', '.').to_f * 60).to_i
# get project
proj = find_project_for(proj_name)
# create time entry
e = Mite::TimeEntry.new(:date_at => timestamp, :minutes => minutes,
:note => comment, :project_id => proj.id)
# add new times
e.save
end
# Find the project with _name_ and return it.
def find_project_for(name)
Mite::Project.all(:params => {:name => name}).first
end
end
# usage with data read from spreadsheet/FX input field
bot = MiteBot.new
bot.login(USER_KEY)
...
# => bot.book_time('15.12', '2,25', 'Introduction of Radar', '')
ConclusionSo what is the point of this blog post besides giving you some ideas how to automate time accounting? I want you to stop moaning about it! Take the initiative. Do something about it. Trust me, developing little automation scripts is fun and rewarding on its own.
 Unfortunately checking Java code for compliance with a given software architecture is not done on every project, as far as I know only a few experts do it. This is not good because "if it's not checked, it's not there". Free tool support for enforcing architectural rules has been lacking since long but recently things have changed. Well, maybe not recently but recently I thought about it :-)
Unfortunately checking Java code for compliance with a given software architecture is not done on every project, as far as I know only a few experts do it. This is not good because "if it's not checked, it's not there". Free tool support for enforcing architectural rules has been lacking since long but recently things have changed. Well, maybe not recently but recently I thought about it :-) Architecture Reviews with Ant
Architecture Reviews with Ant

 Monkey and some Duct Tape...")
 Day 1
Day 1








 The quality of the presentations was excellent. I really liked all of them. This was the most important thing to me because I went there to see the presentations. I didn't care whether the Wi-Fi was slow or if the food was not particularly tasty. I attend conferences to see new things. (Well the food was nothing special, but who cares?) I have attended other conferences before and there were usually a few presentations that were boring or not very good. However, this was not the case with GeeCON! I was pleasantly surprised. Kudos to the GeeCON team and all the speakers. You did a great job.
The quality of the presentations was excellent. I really liked all of them. This was the most important thing to me because I went there to see the presentations. I didn't care whether the Wi-Fi was slow or if the food was not particularly tasty. I attend conferences to see new things. (Well the food was nothing special, but who cares?) I have attended other conferences before and there were usually a few presentations that were boring or not very good. However, this was not the case with GeeCON! I was pleasantly surprised. Kudos to the GeeCON team and all the speakers. You did a great job.











") (
(



")
")

")
")

